Software testing has always been about controlling variables. You set up known inputs, run the code, and check the outputs. When the code is deterministic, that works. But agents built on large language models aren’t deterministic — and that single fact breaks most of what teams have learned about testing over the past few decades.
Below we make the case that environment simulation — replacing the real APIs an agent calls with controlled, programmable stand-ins — is a prerequisite for agent builders. We also explain what these environments need to look like: adversarial by design, stateful across multi-step interactions, built for combinatorial volume, and capable of supporting rigorous evaluation of agent behavior.
Non-determinism makes testing non-negotiable
Testing deterministic software is, comparatively, well-understood territory. You write a test, it passes, and the code does what you expect. Under deadline pressure, teams sometimes ship without full coverage — risky, but the code is predictable enough to reason about without running it.
This is not the case with LLMs and LLM-powered agents. The same prompt, tools, and context can produce different behavior across runs. An agent that correctly sequences four API calls to modify a booking might hallucinate a fifth on the next attempt, or swap the order of two steps for no discernible reason. A single test run tells you almost nothing, and confidence comes from volume: hundreds of runs, not one clean pass.
For classical software, more testing is better; for agents, systematic testing is a prerequisite for deployment. An untested agent means deploying a system whose behavior you’ve never measured — and have no basis to predict. And you don’t really want to do that in production, as this meme (source unknown) epitomizes:

Agent developers we’ve spoken to recently are exploring property-based and fuzzy testing approaches, generating large numbers of scenarios and verifying properties (did the agent complete the task? stay within authorized actions?) rather than matching exact expected outputs. This is still emerging practice, but it maps naturally to systems where you can’t enumerate every possible behavior in advance.
Okay, you might be saying, testing is important - but why simulated environments? Because…
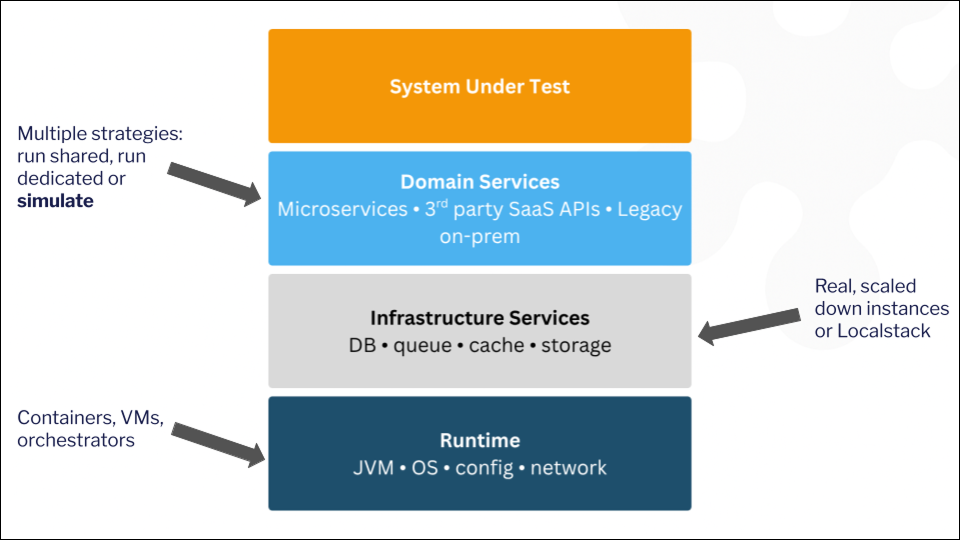
Controlled environments isolate the variable that matters
If your agent’s behavior is inherently non-deterministic, you need everything else to be controlled and repeatable. Environment simulation follows the logic of a controlled experiment. Lock down the API responses that an agent’s tools return — same data, same timing, same error conditions, every run — and the only thing that varies is the agent itself.
Without this control, you can’t benchmark meaningfully. Teams evaluating whether one LLM handles a particular workflow better than another need identical tool responses feeding both models. Otherwise you’re comparing two moving parts at once and your results are noise. Anyone who’s spent a week running agent evaluations against live APIs, only to realize the API itself was drifting between runs, knows how expensive that lesson is.
Simulated environments also solve the practical problem of APIs that don’t exist yet — enterprise agent deployments often target integrations with customer systems that are months from completion, but the agent needs to be developed and benchmarked now.
However, a controlled environment that only serves clean, well-formatted responses is testing a version of reality your agent will never encounter.
Adversarial test design reveals the failure modes worth finding
Simple API mocking simulates the happy path plus a handful of known error codes. You mock a 200 with the expected payload, maybe a 404 and a 500, and you move on. That’s sufficient when the consumer is deterministic code that either handles an error or doesn’t.
Agent testing requires something more… hostile. Because agents make decisions based on the data they receive, the interesting question goes beyond whether an agent handles a clean response correctly. What matters is whether the agent stays on task when the environment works against it — when real-world APIs serve conflicting data, return unexpected nulls, and produce error messages verbose enough to consume a significant chunk of the agent’s available context.
Effective adversarial testing means designing tool responses that are intentionally hostile. Consider:
- Contradictory data — an availability API that says a room is both available and booked, forcing the agent to resolve the conflict or ask for clarification.
- Excessively long responses — stuffing enough detail into a single reply to blow out the agent’s context window and test whether it can still extract what it needs.
- Irrelevant information injection — plausible but off-topic content mixed into responses, tempting the agent to veer off task or incorporate noise into its reasoning.
When deterministic code hits a malformed response, the outcome is binary — it handles the error or it crashes. When an agent hits the same malformed response, it might handle it correctly most of the time, get confused occasionally, and go completely off the rails in a small percentage of runs. You only discover those failure distributions by running the adversarial scenario repeatedly and measuring outcomes — and that’s where realistic environment simulation comes into play.
Every model update resets the clock — and that means a lot of new testing
At the risk of repeating some tropes that you’ve heard before, the AI landscape is changing fast - new models, new agentic setups, new workflows. And often that means you will need to re-test your entire setup from scratch - which can easily become a significant stress test for your entire testing infrastructure.
Consider a moderately complex deployment: a few dozens of distinct agents, each benchmarked across a couple hundred conversation scenarios, with each conversation requiring 5-10 tool calls. If something significant changed (such as a model update), you’re easily looking at tens of thousands of simulated API calls per benchmark pass, and that’s before you account for running the suite more than once.
Now consider what might trigger a full benchmark:
- Every new LLM release demands one
- Every significant prompt change needs validation
- Every adjustment to tool configurations or guardrail settings should be benchmarked before production
Running these benchmarks against real APIs means paying more to get data you can trust less. You hit rate limits that throttle a one-hour benchmark into a daylong crawl. And the real cost goes beyond dollars — it’s epistemic. Live APIs return different data based on server load, cache state, and concurrent modifications. You’ve reintroduced the exact variability you built the benchmark to eliminate.
Ideally, these benchmarks would run without human intervention — wired into CI/CD pipelines, triggering automatically when a new model drops with programmatic setup, execution, and teardown. If spinning up the test environment requires someone clicking through a UI, that person becomes the bottleneck (and their job becomes highly tedious).
Multi-step workflows require stateful simulation
Most agent workflows aren’t single-call operations. A voice agent handling a booking modification might look up the reservation, check alternative dates, modify the booking, confirm changes, and trigger a notification. Each step depends on state created by the previous ones: if the agent modifies a booking to March 15, the mock needs to remember that March 15 is now booked. Otherwise the agent’s next interaction operates on false premises and the test is meaningless.
Classical API mocking is overwhelmingly stateless — request in, response out, no memory between calls. That works for testing a single integration in isolation. It falls apart for agents orchestrating dependent operations across multiple services. The state model doesn’t need to perfectly replicate production, but it needs to be realistic enough that the agent’s multi-step reasoning gets properly exercised.
Closing the feedback loop
Running agents against simulated environments isn’t the end goal. What matters is what you do with the results.
When the environment is held constant across runs, you can compare agent performance with confidence that differences in outcomes are attributable to the agent, not to environmental drift. This is the link between simulation and meaningful evaluation. With deterministic tool responses, you can measure whether a prompt change actually improves task completion or just shifts which failure modes appear. You can replay the exact same scenario after a code change to isolate its impact. You can build regression baselines that hold up over time because the environment isn’t moving underneath you.
Without simulation, evaluation is guesswork. You can observe that an agent succeeded or failed, but you can’t attribute the outcome cleanly. There’s a real difference between “we think GPT-4o is better for this use case” and “we’ve measured that GPT-4o completes this task correctly 94% of the time vs. Claude’s 87%, across 500 runs with identical tool responses.” The second statement is only possible when the environment is locked down.
This is arguably the most compelling reason engineering leaders invest in simulation infrastructure. The simulation makes testing possible; the evaluation it enables makes the investment worthwhile.