Failure in distributed systems and apps is par for the course. What matters is how systems and apps respond to failures. That’s where chaos engineering comes in. We’ve incorporated chaos engineering features into WireMock Cloud because we think it’s a critical capability when you’re developing or testing APIs. Below we give a quick overview of the practice and how it applies to API development more generally.
If you’re already familiar with chaos engineering and are looking to read more about WIreMock-specific chaos features, read our previous article on this topic.
What is chaos engineering, exactly?
Chaos engineering is a methodical approach to software development and testing that’s designed to identify weaknesses. This is achieved by intentionally introducing faults and observing how the system responds. In doing so, dev teams can understand the limits of their applications, ultimately making them more resilient in production environments.
Developed by Netflix in 2011, the significance of chaos engineering lies in its proactive nature. Instead of waiting for unexpected failures to occur and remedying the cause after the fact, it allows teams to prepare for and mitigate potential issues before they impact users.
At the core of chaos engineering are four fundamental principles:
-
Hypothesis: Your hypothesis encompasses educated guesses regarding a system’s behavior under certain conditions. Before conducting chaos experiments, dev teams hypothesize about the system’s performance and response to specific disruptions. In doing so, they set clear expectations and objectives for the experiment.
-
Testing: Testing encompasses controlled experiments that introduce faults and observe how the system responds. These faults can include server crashes, network failures, or any other adverse events that an application might encounter in production. The goal here is to identify weaknesses and understand how different components interact under stress.
-
Blast radius: The blast radius concerns the scope and impact of chaos experiments. It’s important to begin with a small blast radius, meaning that initial experiments should have limited scope to minimize potential damage. Controlling blast radius means that dev teams can safely introduce chaos elements without risking widespread damage and increase the blast radius as confidence and understanding grow.
-
Insight: Insight is about learning from chaos experiments and using gained knowledge to enhance the application. Following experiments, results are analyzed to derive meaningful insights into how the application performs under stress. These help to identify not only the immediate failures but also underlying issues that could lead to bigger problems in the future.
How chaos engineering supports development in API environments
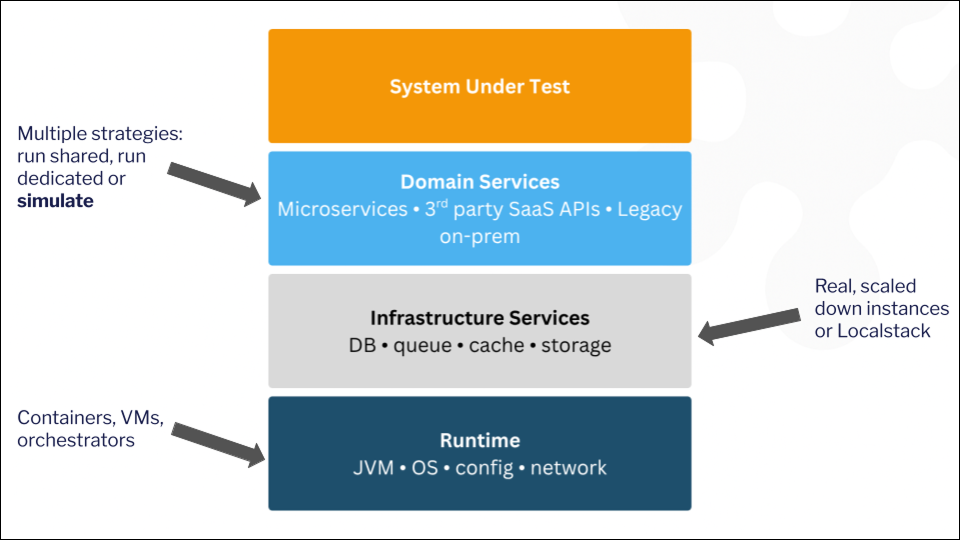
Chaos engineering is becoming an increasingly important practice for teams that operate in heavily API-dependent environments (such as in microservices architecture, or when several 3rd party services are involved).
Testing APIs can create challenges for dev teams. For example, internal APIs can be problematic because of intermittent availability, behaviors that change mid-development, or simply because they are not ready yet when dependent components are being worked on (see: parallel development). Meanwhile, dev teams that rely on third-party APIs for their apps may struggle with rate limits, high costs, and general unreliability stemming from a lack of control over the API. In both cases, ‘traditional’ testing methods have a hard time modeling the unpredictable and, well, chaotic types of situations that can arise when moving these APIs to production.
Chaos engineering offers a solution to many of these testing challenges. By applying chaos engineering principles, dev teams can derive valuable insights into how their apps will behave in production by injecting both predefined error and random chaos elements. This is especially helpful when combined with API mocking (as WireMock Cloud allows you to do), since you can easily modify the failure states and simulate a wide range of scenarios and issues, which might be difficult to do when working with the live API. This information can then be used to engineer solutions to problems such as 5xx errors, timeouts, and inconsistent error handling. The ultimate result is a product that’s more robust and resilient, which in turn leads to higher user satisfaction.
5 considerations for implementing chaos engineering in API consumer or producer workflows
1. Plan and scope your experiments
Determine the specific aspects of your APIs that you want to test. For example, you might want to test resilience to API rate limiting, latency issues, or unexpected response formats. Create a hypothesis about how your system will behave under API stress and determine the metrics you’ll use to measure success. Define a scope for your experiments so they don’t cause unintended disruptions to your API consumers.
2. Select tools for chaos engineering
Choose tools that specialize in API testing and chaos engineering. Look for solutions that can simulate API failures, latency, and unexpected responses. If you’re using WireMock Cloud, you already have built-in chaos engineering features when designing your mock APIs. If you’re looking to build from scratch, you can start with open source choices such as Netflix’s own Chaos Monkey library.
You’ve also got the option of building your own chaos experiments from the ground up. This will require a lot of grunt work to achieve and given the wide variety of chaos tooling available, there’s not very much point in doing it manually.
3. Execute your experiments
Your experiments should begin with a small blast radius, targeting a limited part of the app or system to minimize risk. Carefully monitor the system’s behavior and ensure that you have fail-safes in place to quickly roll back any changes if necessary.
If you’re testing an app in production and can’t use a staging environment, then you should limit your experiments to off-peak hours to avoid impacting any live users. Document every step of the experiment, including the conditions, actions taken, and immediate observations. Execution should be methodical and closely aligned with the planned scope.
4. Analyze results
Compare your actual outcomes with your initial hypothesis to identify any discrepancies. These are your areas for improvement. Also, focus on understanding how your app responded to the API failures you introduced and whether any unexpected behaviors occurred.
Analyze the metrics you defined during the planning phase to assess the impact on performance, reliability, and user experience. This analysis should also provide plenty of insight into the app’s weak points and potential areas for enhancement.
5. Iterate
Chaos engineering, like most development processes, is iterative. Based on the insights gained from your experiments, implement changes to improve system performance and resilience. This might involve optimizing code, enhancing infrastructure, or refining your operational practices.
Design new experiments and run them again after changes have been made. This will help you validate these changes and continue the cycle of testing and learning.
Make chaos engineering part of your API testing and development with WireMock Cloud
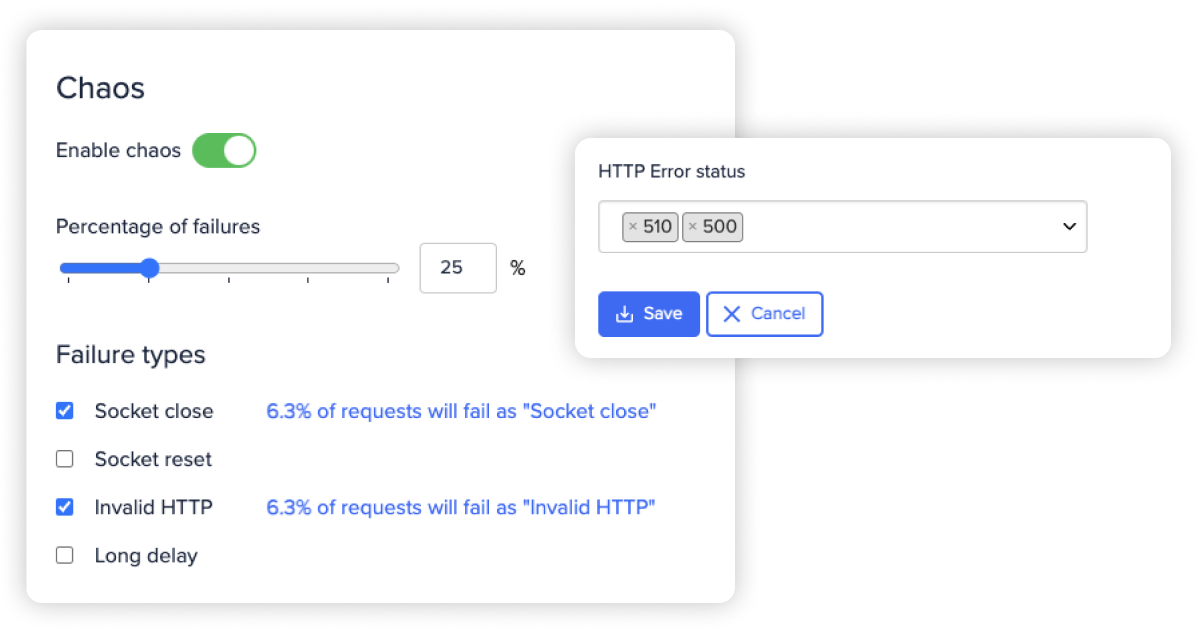
WireMock Cloud helps dev teams move to production faster by making it easy to mock the APIs they depend on. Instead of piecing together disparate tools and solutions to get the chaos functionality you need, you can use WireMock Cloud to create copies of the APIs you need to test, and then introduce complex failure scenarios with our integrated Chaos* *functionality.
WireMock Cloud puts you in control. Introduce predetermined errors and failure states to see how your app responds to specific scenarios, such as socket resets and closures or invalid HTTP errors. Alternatively, introduce a wide range of random chaos elements and error statuses for more realistic integration testing and avoiding disasters in production.
Read our previous tutorial to learn how it works in practice; or try it out yourself by signing up for a free forever account.