Adapted from my talk at GeeCON Kraków 2026. You can watch the full recording on YouTube.
Test environments are something most of us take for granted. If you’re a professional software developer, there’s a good chance your code moves through a familiar chain of pre-production environments - dev, QA, staging, maybe a UAT layer if your organization is feeling expensive - each one a scaled-down replica of production, each one supposedly making your release safer.
When I gave this talk at GeeCON recently, I asked the room two questions. First: who works with an environment setup like this? Nearly every hand went up. Second: keep your hand up if it never causes you problems, never slows you down, is never the reason you can’t ship. One hand stayed up. I’m glad someone’s having a good time with it.
For everyone else, I want to make an argument: these environments were already creaking under microservices and faster delivery cycles, and the arrival of AI coding agents is threatening to finish them off. The model needs to change - and the same AI that’s breaking it can help us build the replacement.
Shared test environments were already failing us
The classic long-lived, shared, production-replica environment has four chronic problems, and you could have written this list at any point in the last fifteen years:
- Slow. Slow at runtime, slow to configure, slow to get test data into. Every interaction has friction.
- Unstable. Shared environments are shared — other teams are deploying unfinished code into them, changing data, and putting load on them in unpredictable ways. Your testing workload is constantly interfered with by everyone else’s.
- Non-deterministic. Testing depends on consistency: perform the same action, get the same result. When data shifts under you between runs, you can’t trust a pass or a failure.
- Hard to observe. Verifying an outcome often means finding out whether a record landed in somebody else’s database, three services away from anything you can see in a UI.
Irritating, but survivable - humans are quite good at working around broken things. We retry, we make judgment calls, we walk over the broken step without thinking about it. That coping ability is exactly what’s about to stop scaling.
AI coding agents turn an annoyance into a bottleneck
There are two distinct ways generative AI collides with your environments, and they’re worth separating
The first is using AI in your SDLC - coding agents, AI code review, all the ways teams are trying to move faster. The constraint here is simple arithmetic. If you’re generating ten times as much unverified code, everything downstream that exists to verify it comes under immense pressure - and integrated test environments sit squarely downstream. I like Jason Gorman’s way of putting it: just because you’ve made the car faster doesn’t mean the traffic gets faster.
Flakiness gets worse too, because agents handle it far less gracefully than people do. A human sees a test fail on a random network blip, shrugs, and re-runs it. An AI coding agent sees a failing test and concludes it must have broken the code. I’ve had this happen more than once: I ask an agent to make a change and re-run the regression suite, one test fails for some transient reason, and the agent helpfully rewrites a pile of perfectly working code to “fix” it. You come back half an hour later to a mess. A flaky environment doesn’t slow an agent down so much as send it off in the wrong direction entirely.
The second collision is building AI-powered applications. A new body of test practice is emerging around LLM-based systems - evals, where an LLM drives a test and scores the output of another LLM. These are slow by construction (you’ve got two models in the loop), so getting any throughput across a matrix of models and tasks demands massive parallelism - far more than classical testing ever did. Try running that against one shared, rate-limited staging environment.
Evals also demand much stronger determinism. Your system under test is already non-deterministic; if the environment around it introduces more randomness, you’re modifying confounding variables. You can no longer tell whether a score moved because of your prompt change or because the test data shifted overnight.
So: more code to verify, agents that can’t tolerate flakiness, and a style of testing that needs parallelism and determinism in quantities the old model can’t supply. That’s why I’d say that in the GenAI era, the shared production-replica environment is becoming untenable.
What is a test environment, really?
Before talking about alternatives, we need a working definition - because if I asked five people what an environment is, I’d get five coherent and completely different answers.
Here’s mine: a test environment is whatever provides implementations of all the contracts expected by the software under test. Those contracts fall into layers with very different characteristics:
- The runtime - compute, containers, orchestration. The most solved layer of the stack. Docker and friends give you a faithful production-like runtime almost for free, so I won’t dwell on it.
- Infrastructure services - databases, queues, caches. Superficially “just network services,” but they’re commodities: there’s an open-source version you can bottle in a container, and your experience of running it is the same as everyone else’s. Run the real thing scaled down, or something like LocalStack for cloud services.
Domain services - the APIs that actually run your business: your microservices, plus the third-party APIs handling payments, orders, fulfillment, analytics. This is where every hard environment problem lives. They have their own dependency cascades and data requirements. Third-party sandboxes may be flaky, heavily rate-limited, or simply absent. Legacy systems run on bare metal you can’t replicate. Even your own microservices multiply into a feeding-and-watering burden nobody wants.
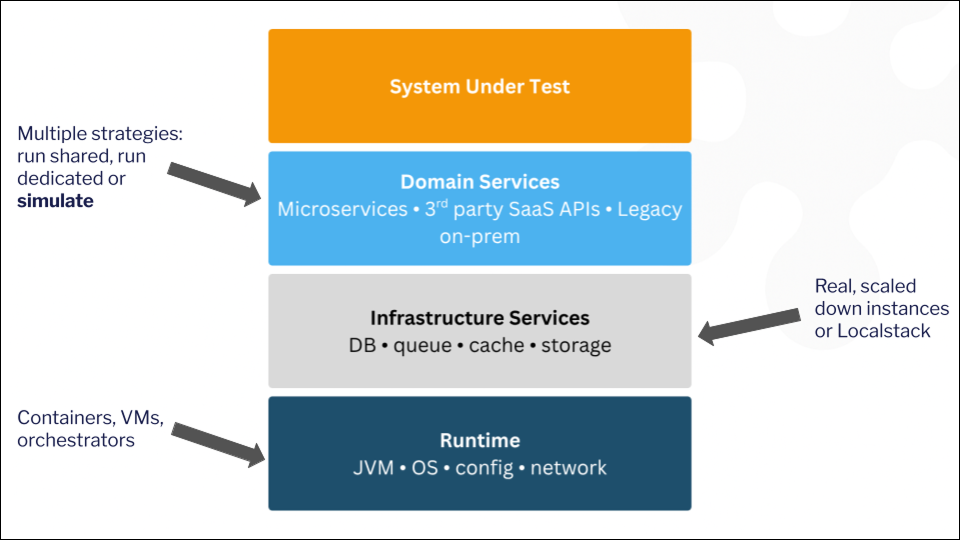
Conflating those last two categories - “they’re both just network services” - is a mistake I see a lot of teams make. Infrastructure services are a solved problem. Domain services need a different tool: API simulation.
Simulation lets you right-size the environment to the test
When you simulate an API, you’re substituting an implementation to make a deliberate trade: you give up some realism and get back speed, reliability, and determinism - precisely the properties the AI era demands. And simulation isn’t all-or-nothing. There’s a progression of environment shapes it unlocks:
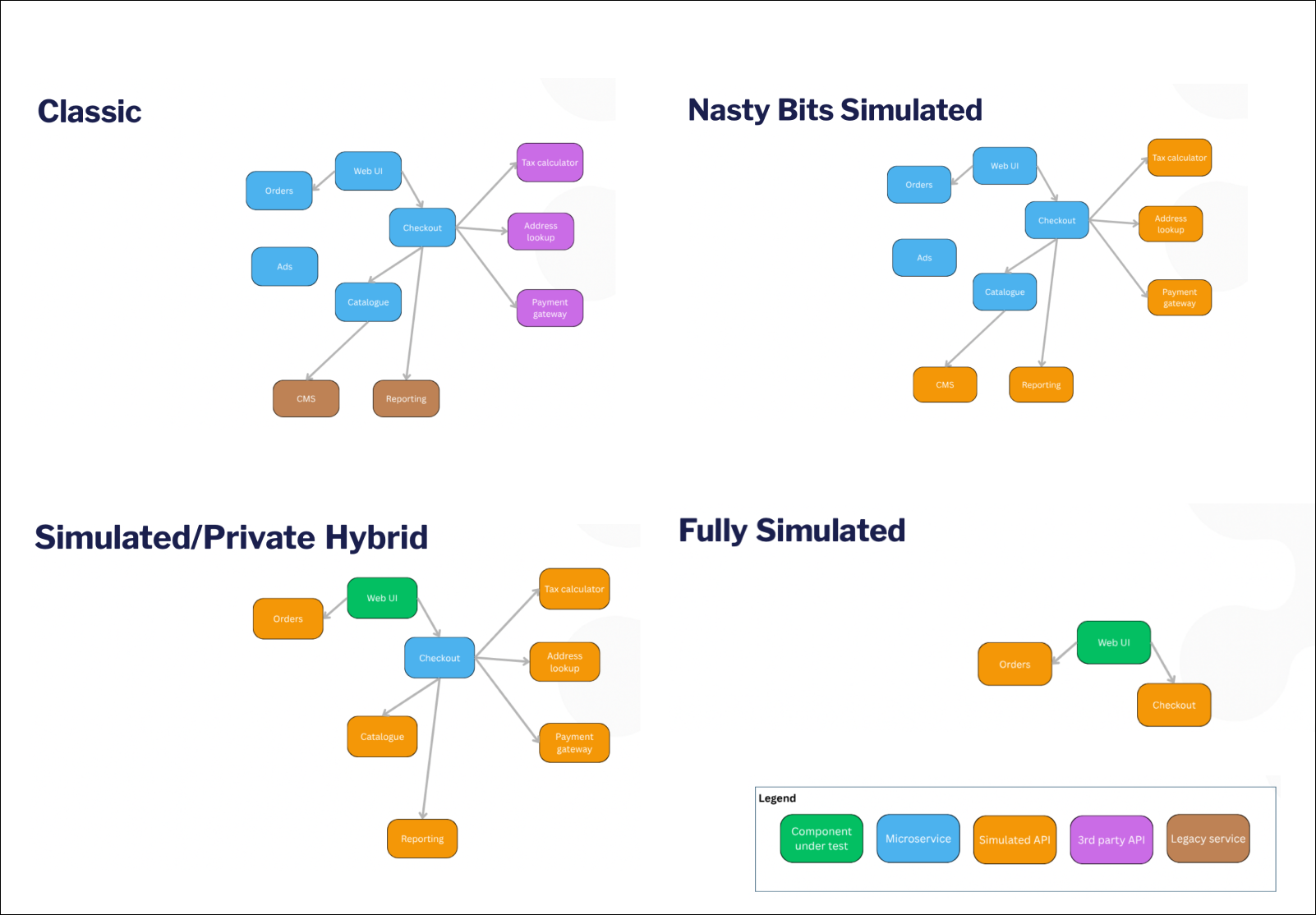
Simulate the nasty bits. Keep your modern, operable services real; simulate the third-party APIs and legacy systems beyond your control. Many of our customers start here.
Bound the collaboration under test. Testing that your web UI and checkout service integrate correctly? Run those two for real and simulate everything at the boundary. Environments this small can be stood up per pull request and thrown away afterwards - ephemeral environments become practical instead of aspirational.
Isolate a single service. Simulate its direct dependencies only. The smallest, fastest, most deterministic way to work.
None of these is the one true answer. The skill is matching the environment to what you’re actually trying to test. Take a checkout test asserting that sales tax is added correctly. With a real tax-calculation API in the loop, you’re testing the tax engine’s behavior and your integration with it, and your assertions depend on a pile of preconditions about products and locations. If what you actually care about is the checkout logic, you can simulate the tax API - item one returns $2.40, item two returns zero - and assert on the sum. Faster, simpler, and a more precise statement of intent. If you’ve done much object mocking, the reasoning will feel familiar; the same judgment applies a level up.
One caveat I always give: every simulation is an assumption boundary. It encodes your understanding of how a dependency behaves, and assumptions need validating. Keep some integrated testing for that - and for the workflow-level failures and capacity questions that only show up when real services run together. Be deliberate and minimal about what you insist on testing in integrated environments, and shift the bulk of the workload to small, short-lived, simulated ones.
Fighting AI problems with AI solutions
If this approach is so attractive, why doesn’t everyone already work this way? Engineering effort. Building good simulations takes work, there’s a learning curve, and the maintenance is worse: in a big microservice estate, real APIs change constantly, and unmaintained simulations drift until your tests pass against an API that no longer exists.
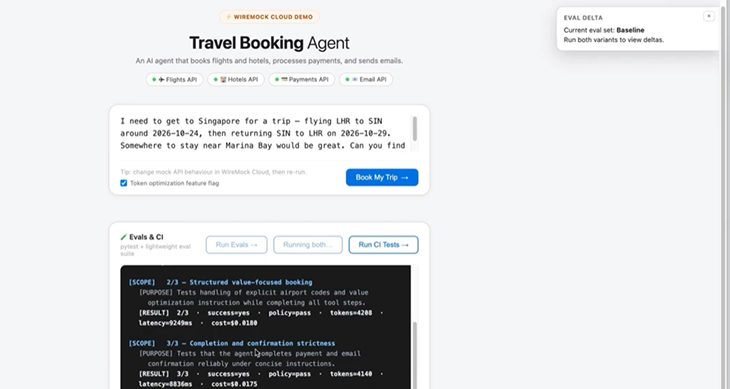
But this is exactly the kind of work generative AI is good at! It’s grunt work: take this description of an API and render it into another format. It’s far simpler than asking an agent to make changes inside a complex codebase. We’ve been building out a library of pre-built API simulations in WireMock Cloud this way, using a set of Agent Skills we’ve been incubating - but the techniques are tool-agnostic, and you can apply them with WireMock open source or other stacks.
The workflow that works splits into stages:
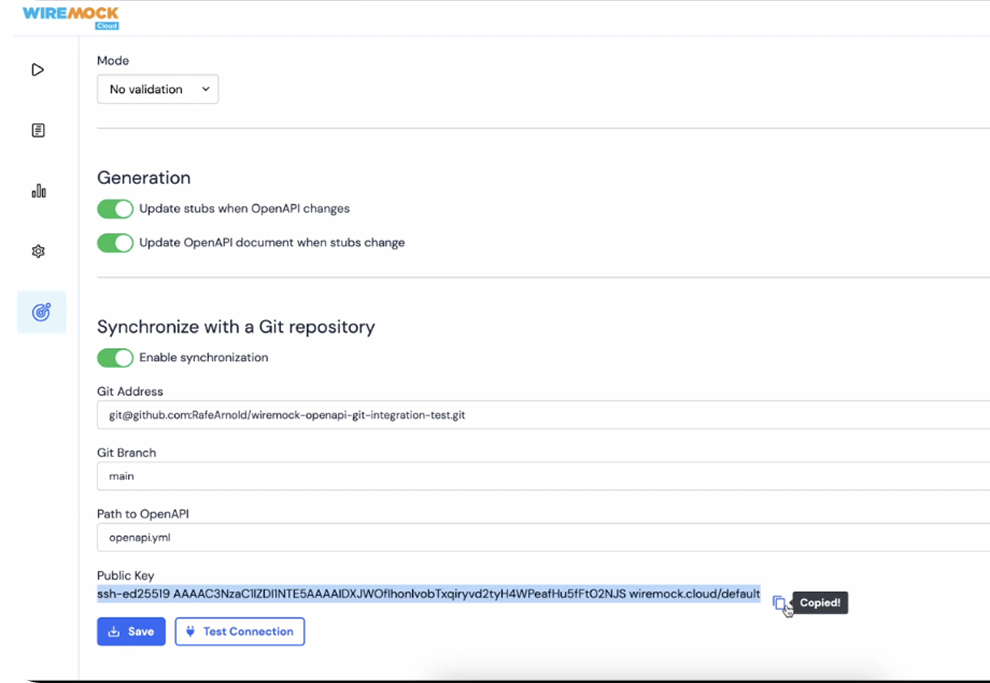
- Generation. Point your coding agent - Claude Code, Cursor, GitHub Copilot - at a source of truth and ask for a simulation. Good sources, roughly in order: actual service source code if you’re inside the org boundary (one customer wires Sourcegraph into their agent so it finds and reads the implementation of any API it needs to mock); validated OpenAPI descriptions - ones that generate docs or are exercised in production processes, not the write-once specs rotting in repos; and vendor SDKs, which tend to be well-validated because customers depend on them.
- Verification. Agents get bored, miss endpoints, hallucinate fields that aren’t in any schema. So verify mechanically: run generated traffic through an OpenAPI validator and treat every error as a defect in the simulation, or have the agent generate a test suite against the vendor SDK - statically typed SDKs are great here, because structural problems surface as binding failures. The same verification loop guards against drift on every later update.
- Enhancement. Move along the realism scale as your testing goals demand - make the simulation stateful, add error responses and defaults, enrich the data - re-running verification each time so improvements don’t break contract conformance. If you have a real sandbox available, record traffic through a proxy first and enhance from that very realistic starting point.
With combinations of these, we’ve found simulations of fairly complex APIs converge on something accurate and usable in a largely automated fashion. The drift problem - the thing that historically made this strategy expensive - becomes a background process. (Within WireMock Cloud, the MCP server and Agent Skills run this whole loop from inside your coding agent, iterating until validation errors hit zero.)
Something you can try today
You don’t have to do any of this in one go. Peel off one service. Build it a dedicated, simulated environment fitted to a specific testing goal, adapt part of your test suite, and run it in parallel with your existing integration tests until you trust it.
And if your organization has AI adoption goals - most do now - this is an easy thing to sell. It’s lower-risk than generating production code with AI, and it attacks a productivity bottleneck you’re already feeling, one that gets worse with every coding agent you switch on.
Long-lived, shared production replicas served us for a couple of decades. The future of test environments is smaller, shorter-lived, more deterministic, and increasingly built and maintained by the same AI agents that made the old model impossible.
Related resources
- Watch the full talk on YouTube
- Check out the AI-generated demo project from the talk shows the generation → verification → enhancement workflow end to end, commit by commit.
- Get a demo of WireMock Cloud